
Support Dropout on XGBoost
Introduction
Gradient Boosting Trees algorithms(especially XGBoost) give awesome performance in lots of competitions. They combine a huge number of regression trees with small learning rate. In this situation, trees added early are significance and trees added late are unimportant. DART algorithm drops trees added earlier to level contributions.
Recently, Rasmi et.al proposed a new method to add dropout techniques from deep neural nets community to boosted trees, and reported better results in some situations. We are glad to announce that DART is now supported in XGBoost, taking fully benefit of all xgboost optimizations to this new technique.
Original paper
Rashmi Korlakai Vinayak, Ran Gilad-Bachrach. “DART: Dropouts meet Multiple Additive Regression Trees.” JMLR
Features
- Drop trees in order to solve the over-fitting.
- Trivial trees (to correct trivial errors) may be prevented.
Because the randomness introduced in the training, expect the following few difference.
- Training can be slower than
gbtreebecause the random dropout prevents usage of prediction buffer. - The early stop might not be stable, due to the randomness.
How it works
- In
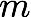 th training round, suppose
th training round, suppose 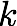 trees are selected drop.
trees are selected drop. - Let
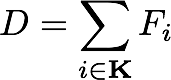 be leaf scores of dropped trees and
be leaf scores of dropped trees and 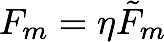 be leaf scores of a new tree.
be leaf scores of a new tree. - The objective function is following:
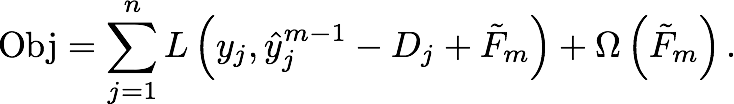
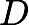 and
and 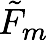 are overshooting, so using scale factor
are overshooting, so using scale factor
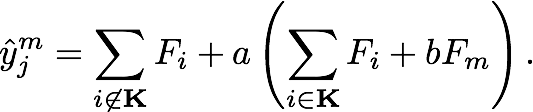
Parameters
booster
dart
This booster inherits gbtree, so dart has also eta, gamma, max_depth and so on.
Additional parameters are noted below.
sample_type
type of sampling algorithm.
uniform: (default) dropped trees are selected uniformly.weighted: dropped trees are selected in proportion to weight.
normalize_type
type of normalization algorithm.
tree: (default) New trees have the same weight of each of dropped trees.
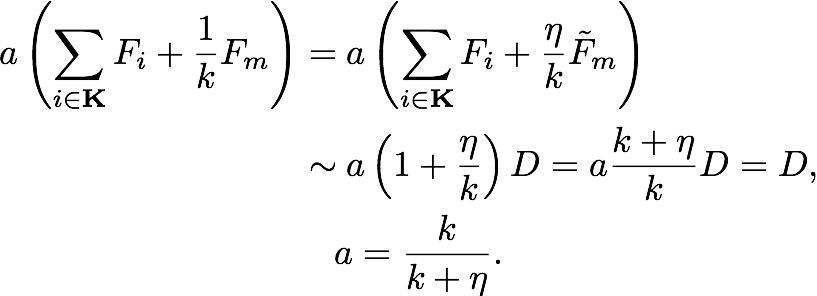
forest: New trees have the same weight of sum of dropped trees (forest).
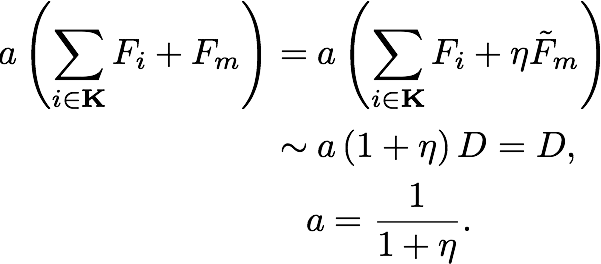
rate_drop
dropout rate.
- The higher this value is, the more trees are selected drop.
- range: [0.0, 1.0]
skip_drop
probability of skipping dropout.
- If a dropout is skipped, new tree is added in the same manner as
gbtree. - range: [0.0, 1.0]
Sample Script
Python
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {'booster': 'dart',
'max_depth': 5, 'learning_rate': 0.1,
'objective': 'binary:logistic', 'silent': True,
'sample_type': 'uniform',
'normalize_type': 'tree',
'rate_drop': 0.1,
'skip_drop': 0.5}
num_round = 50
bst = xgb.train(param, dtrain, num_round)
# make prediction
# ntree_limit must not be 0
preds = bst.predict(dtest, ntree_limit=num_round)
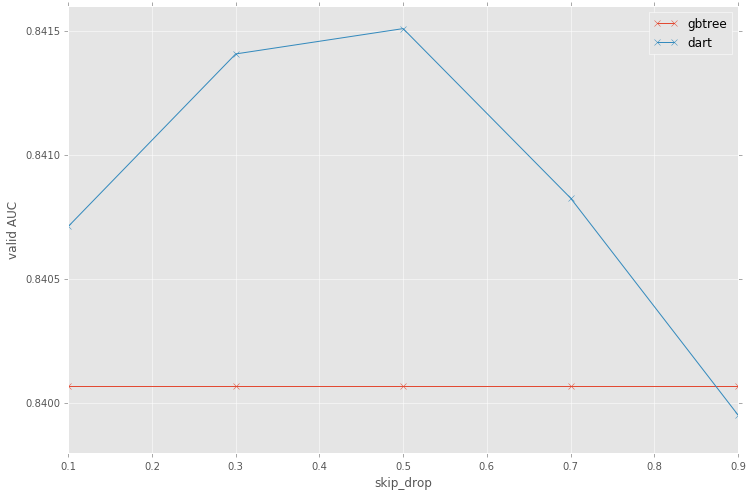
Numerical Example
Comparing dart with gbtree using the dataset from Santander Customer Satisfaction.
In this experiment, dart shows better classification performance.
The code is here (external link).
Acknowledgements
The author is grateful to Tianqi Chen for helpful advice on implementation and documentation.
Bio
This feature is contributed by Yoshinori Nakano.
Yoshinori Nakano works as a data analyst in the field of credit scoring. He ponders how to solve the linear separable problems using tree based models.
This is a modified verison of his japanese blog post(external link).